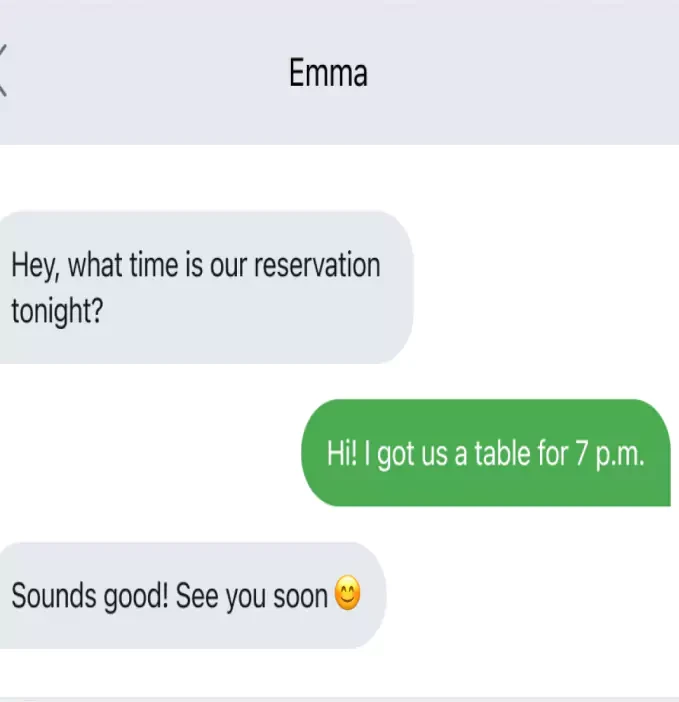
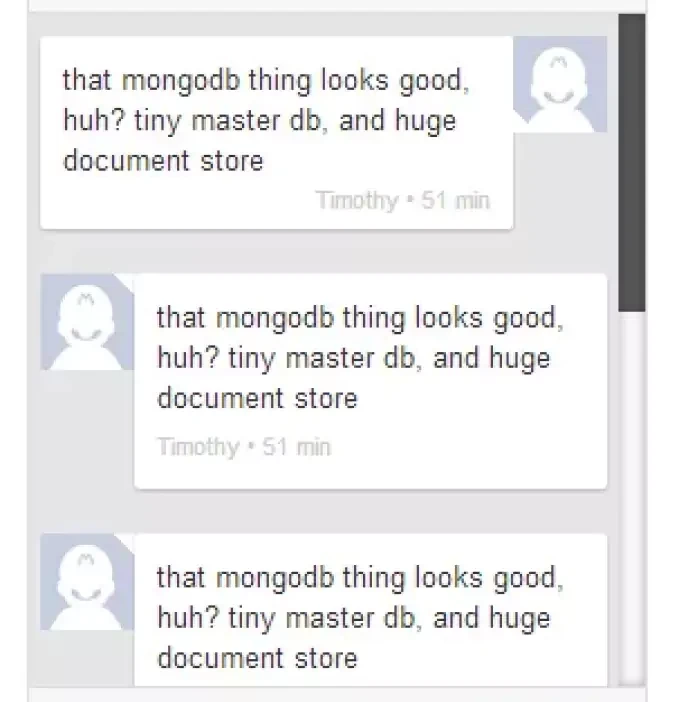
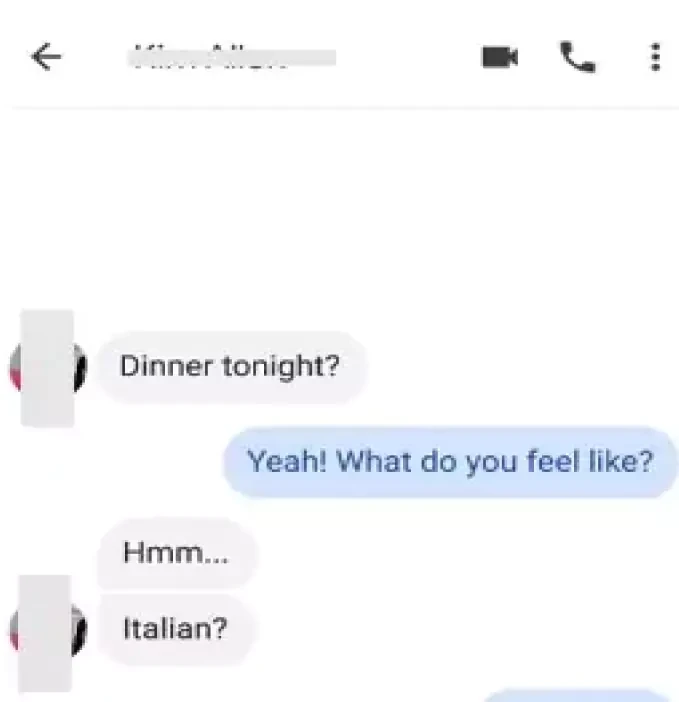
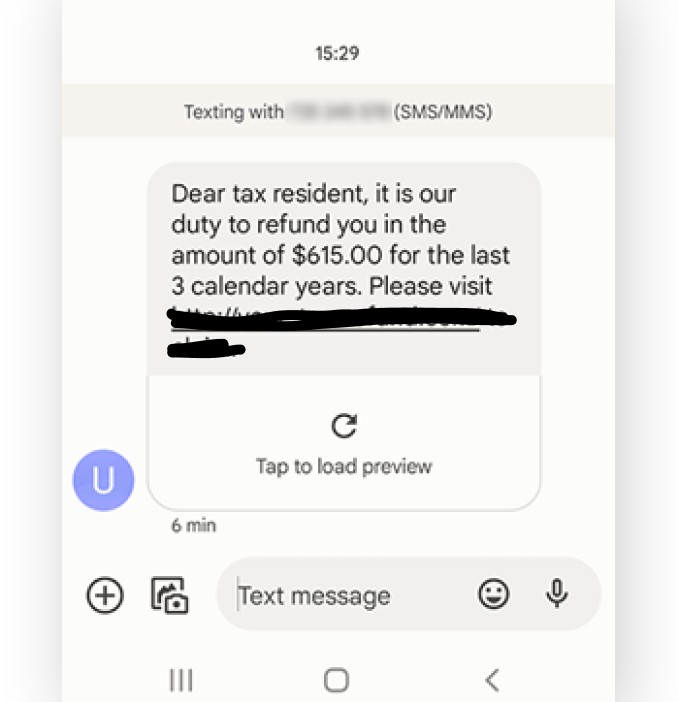
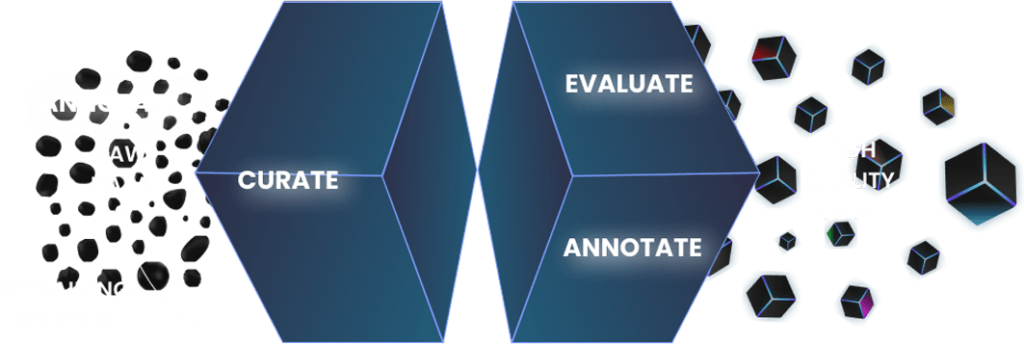
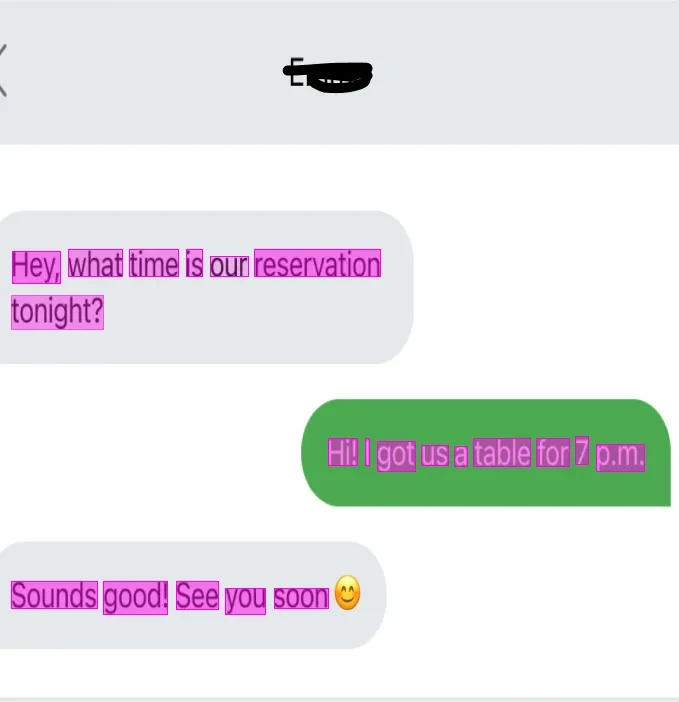
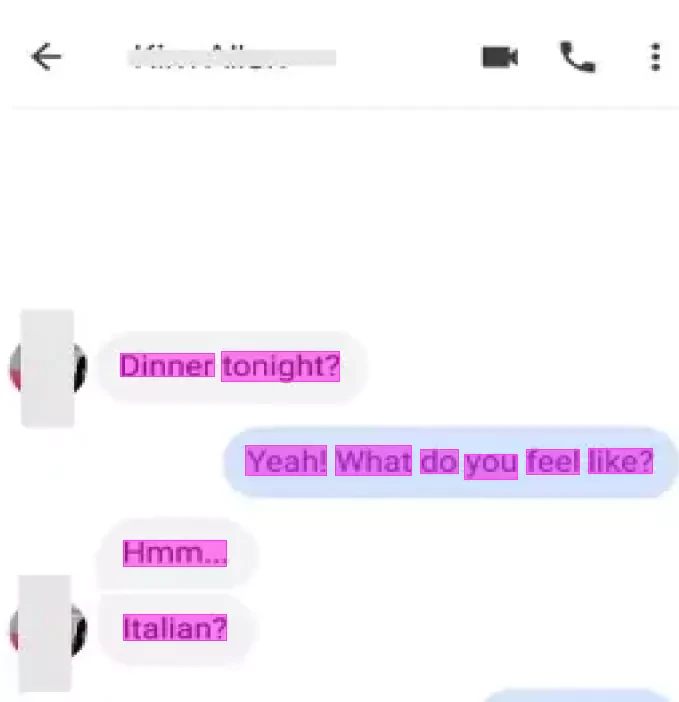
The “SMS Corpus with POS and NER” project showcases our commitment to providing high-quality, annotated datasets for advancing the field of natural language processing and machine learning. This carefully curated and annotated SMS corpus is an invaluable resource for developing sophisticated language models that can understand and interpret human text effectively. Our dataset stands as a testament to our expertise in data collection and annotation, offering a robust foundation for future technological advancements in various applications.