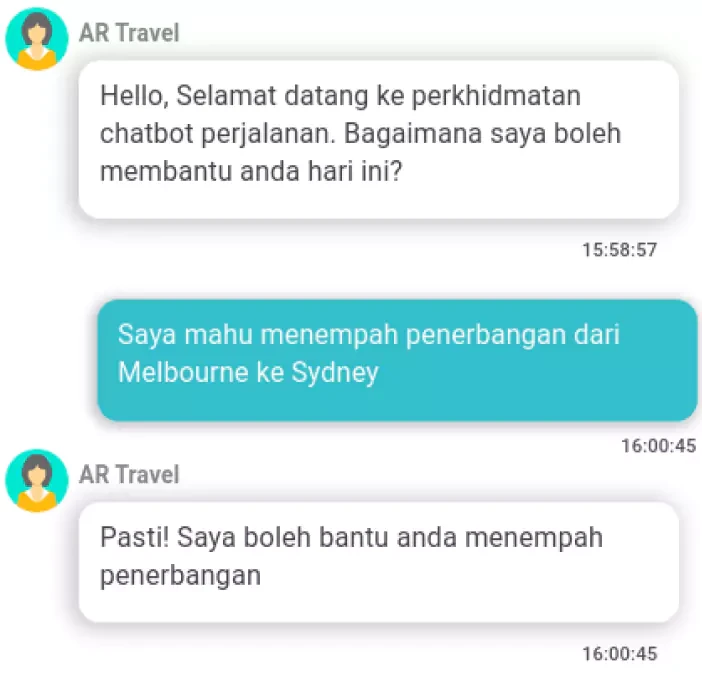
The “Malay Text Files” project stands as a testament to our commitment to advancing machine learning capabilities in understanding the Malay language. With a rich and diverse dataset, complemented by thorough annotations and stringent quality control, we have laid the groundwork for developing more nuanced and effective language processing tools. This initiative not only enriches the technological landscape but also bridges linguistic barriers, fostering better communication and understanding in the digital age.