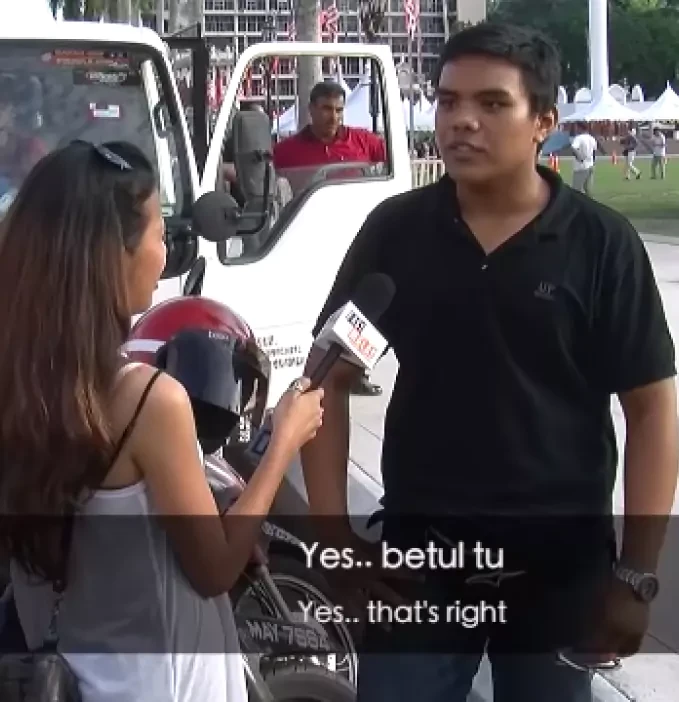
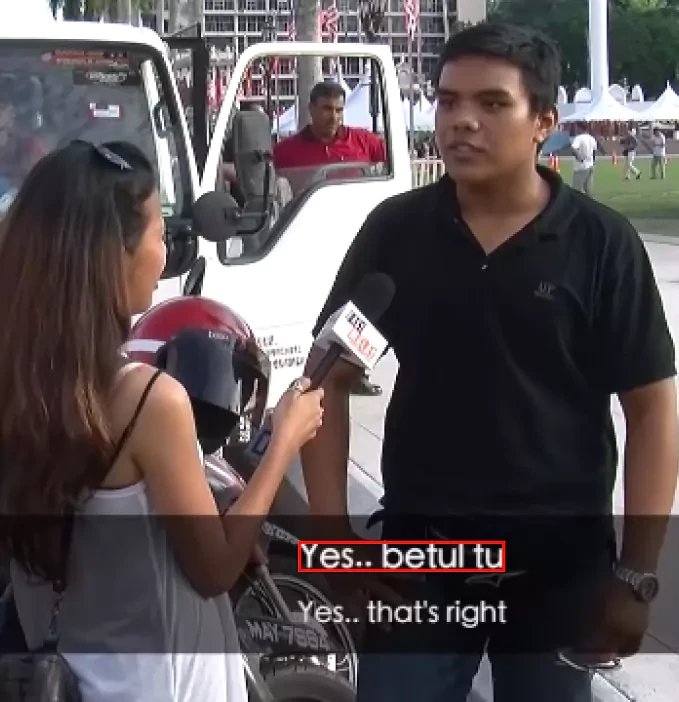
The project encompasses the collection and annotation of Malay language conversations from diverse sources. This includes dialogues from native speakers, public domain resources, and scripted scenarios to ensure a rich variety of conversational contexts.