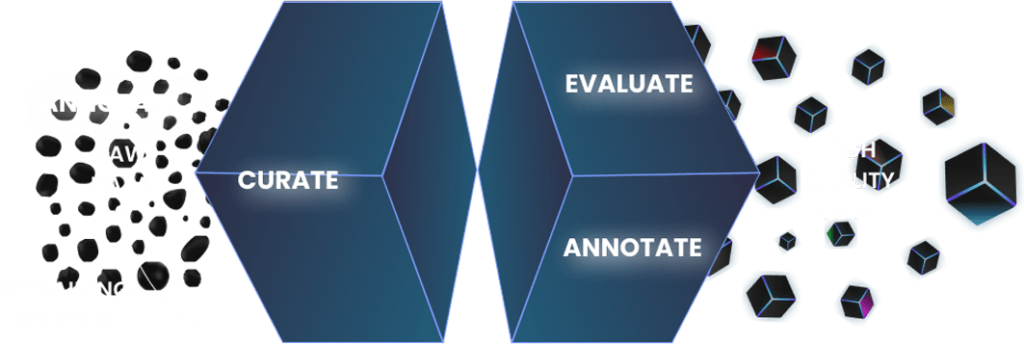
The “Hebrew Media Audio Dataset” is a pivotal resource for advancing Hebrew speech recognition technology. With a vast collection of diverse, accurately annotated audio samples, this dataset is instrumental in developing sophisticated speech recognition systems. It plays a significant role in enhancing media content accessibility, language learning tools, and automated transcription services in Hebrew, fostering technological growth and linguistic inclusivity.